


Tabela de links
Resumo e 1. Introdução
- Método proposto: quantizado Dylora
- Experiências e avaliação
- Sobre o comportamento semi-derrotado de Qdylora
- Conclusão, limitações e referências
A. Material suplementar
A.1. Hyperparameters
A.2. Qualidade de texto gerada
Resumo
Os grandes modelos de idiomas Finetuning requer uma grande memória da GPU, restringindo a opção de adquirir modelos maiores. Enquanto a versão quantizada da técnica de adaptação de baixo rank, chamada Qlora, alivia significativamente esse problema, descobrir que a classificação eficiente da LORA ainda é desafiadora. Além disso, o QLORA é treinado em uma classificação predefinida e, portanto, não pode ser reconfigurada para seus escalões mais baixos sem exigir etapas mais finas. Este artigo propõe a adaptação dinâmica de baixo rank-rank-como uma abordagem de quantização eficiente para a adaptação dinâmica de baixo rank. Motivada pela dinâmica Lora, Qdylora é capaz de Finetune LLMs com eficiência em um conjunto de fileiras de Lora predefinidas. O QDYLORA permite o Falcon-40B de ajuste fino para as classificações de 1 a 64 em um único V100-GPU de 32 GB através de uma rodada de ajuste fino. Os resultados experimentais mostram que o QDYLORA é competitivo para a qlora e supera o emprego ao empregar sua classificação ideal.
1 Introdução
A popularidade da adoção de grandes modelos de idiomas (LLMS) em uma gama diversificada de tarefas a jusante aumentou rapidamente nos últimos dois anos. A Finetuning LLMS tornou -se necessária para melhorar seu desempenho e introduzir comportamentos desejados, evitando saídas indesejadas (Ding et al., 2023). No entanto, à medida que o tamanho desses modelos aumenta, os custos de ajuste fino se tornam mais caros. Isso levou a um grande corpo de pesquisa que se concentra em melhorar a eficiência do estágio de ajuste fino (Liu et al., 2022; Mao et al., 2021; Hu et al., 2021; Edalati et al., 2022; Sung et al., 2022).
O adaptador de baixo rank (Lora) (Hu et al., 2021) é um método bem conhecido, eficiente em termos de parâmetro (PEFT) que reduz os requisitos de memória durante o ajuste fino, congelando o modelo base e atualizando um pequeno conjunto de parâmetros treináveis na forma de multiplicação de matriz de baixa classificação adicionada a matrizes de matrizes. No entanto, a demanda de memória durante o ajuste fina permanece substancial devido à necessidade de um passe para trás pelo modelo de base congelada durante a ascendência estocástica do gradiente.
Pesquisas recentes se concentraram em reduzir ainda mais o uso da memória, projetando novos módulos com eficiência de parâmetro que podem ser ajustados sem necessidades de gradientes dos modelos básicos (Sung et al., 2022). Como alternativa, os pesquisadores exploraram a combinação de outras estratégias de eficiência com métodos de ajuste com eficiência de parâmetro (Kwon et al., 2022; Dettmers et al., 2023).
Entre essas abordagens, Qlora (Dettmers et al., 2023) se destaca como um método de ajuste fino recente e altamente eficiente que diminui drasticamente o uso da memória. Ele permite o ajuste fino de um modelo de 65 bilhões de parâmetros em uma única GPU de 48 GB, mantendo o desempenho completo de ajuste fino de 16 bits. A Qlora alcança isso empregando normandfloat de 4 bits (NF4), quantização dupla e otimizadores de paginação, bem como módulos LORA.
No entanto, outro desafio significativo ao utilizar os módulos LORA é a necessidade de ajustar sua classificação como hiperparâmetro. Diferentes tarefas podem exigir módulos Lora de classificações variadas. De fato, é evidente nos resultados experimentais no artigo de Lora que o desempenho dos modelos varia muito com classificações diferentes, e não há uma tendência clara indicando a classificação ideal. Por outro lado, qualquer ajuste hiperparâmetro para encontrar a classificação ideal contradiz o objetivo principal do ajuste eficiente e não é viável para modelos muito grandes. Além disso, ao implantar uma rede neural em diversos dispositivos com configurações variadas, o uso de classificações mais altas pode se tornar problemático para dispositivos altamente sensíveis devido ao aumento da contagem de parâmetros. Para resolver isso, geralmente é preciso escolher entre o treinamento de vários modelos adaptados a diferentes configurações de dispositivos ou a determinação da classificação ideal para cada dispositivo e tarefa. No entanto, esse processo é caro e demorado, mesmo ao usar técnicas como a Lora.
![Tabela 1: Uma comparação entre Qlora e Qdylora no benchmark MMLU, relatando resultados de testes de 5 tiros para LLMs de tamanhos variados. Qdylora é avaliado em fileiras [1,2,4,8,16,32,64] E a melhor classificação é relatada entre colchetes.](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Tabela 1: Uma comparação entre Qlora e Qdylora no benchmark MMLU, relatando resultados de testes de 5 tiros para LLMs de tamanhos variados. Qdylora é avaliado em fileiras [1,2,4,8,16,32,64] E a melhor classificação é relatada entre colchetes.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-ig033k7.png?auto=format&fit=max&w=1920)
Dylora (Valipour et al., 2022), é um método PEFT recente que visa abordar esses desafios, empregando um adaptador dinâmico de baixo rank (Dylora). Inspirado no abandono aninhado, esse método tem como objetivo ordenar as representações do gargalo nos módulos adaptadores de baixo rank. Em vez de treinar blocos de Lora com uma classificação fixa, Dylora estende o treinamento para abranger um espectro de fileiras de maneira classificada. Os módulos PEFT de baixo rank resultante não apenas fornecem maior flexibilidade durante a inferência, permitindo a seleção de diferentes fileiras, dependendo do contexto, mas também demonstram desempenho superior em comparação com o LORA, tudo sem impor nenhum tempo de treinamento adicional.
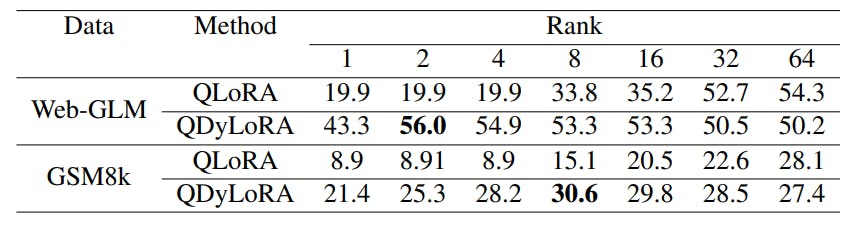
Neste artigo, empregamos o método Dylora Peft em conjunto com o esquema de quantização utilizado no trabalho de Qlora, resultando em Qdylora. Qdylora tem todos os benefícios acima mencionados de Dylora, mas com redução significativa da memória durante o treinamento e a inferência por quantização de 4 bits. Utilizamos Qdylora para ajuste fino eficiente dos modelos LLAMA-7B, LLAMA13B e FALCON-40B em fileiras que variam de 1 a 64, todas em uma única GPU de 32 GB V100. Depois de sintonizados, determinamos a classificação ideal inferindo o modelo no conjunto de testes. Nossos resultados revelam que a classificação ideal pode ser bastante baixa, mas supera a Qlora.
1.1 Trabalho relacionado
Métodos de PEFT de baixo rank Esses métodos visam ajustar os LLMs pré-treinados para tarefas específicas, minimizando os recursos computacionais e de memória. As técnicas de adaptação de baixo rank foram inspiradas por (Aghajanyan et al., 2020), demonstrando que os modelos de linguagem pré-treinados possuem uma baixa dimensão intrínseca. Desde então, vários trabalhos exploraram a incorporação de parâmetros treináveis na forma de projeção/projeção para baixo de baixo rank durante o ajuste fino. Em (Houlsby et al., 2019), o módulo adaptador inclui uma projeção de baixo, uma função não linear, uma projeção UP e uma conexão residual. Esses módulos são inseridos sequencialmente após a Rede Feed-Forward (FFN) ou blocos de atenção.
Além disso, (He et al., 2021) estende o conceito de adaptador, introduzindo módulos treináveis que são executados em paralelo (PA) com o módulo original de Modelo de Linguagem Pré-treinado (PLM). Como resultado dessa extensão, a AF demonstrou melhor desempenho em comparação com o método do adaptador original. Uma abordagem notável entre essas técnicas é Lora (Hu et al., 2021), que introduz a projeção de baixo rank/projeção para baixo em várias matrizes dentro de um PLM. Este método oferece inferência eficiente, integrando perfeitamente o módulo adaptador nas matrizes de peso do modelo original.
Métodos PEFT com reconhecimento de quantização Alphatuning (Kwon et al., 2022), pretende combinar adaptação e compressão do modelo com eficiência de parâmetros. O ajuste do alfa alcança isso empregando quantização pós-treinamento, que envolve a conversão dos parâmetros de precisão completa do modelo de linguagem pré-treinado em parâmetros binários e fatores de escala separados. Durante a adaptação, os valores binários permanecem fixos para todas as tarefas, enquanto os fatores de escala são ajustados para a tarefa específica a jusante.
Qlora (Dettmers et al., 2023) é um PEFT mais recente consciente da quantização que combina um adaptador de baixo rank com quantização normal de 4 bits (NF4) e quantização dupla (DQ) do modelo base para otimizar o uso da memória. O NF4 garante uma distribuição ideal dos valores nas caixas de quantização, simplificando o processo quando os tensores de entrada têm uma distribuição fixa. O DQ reduz ainda mais a sobrecarga da memória quantizando as constantes de quantização.
Para gerenciar a memória durante o verificação de gradiente, a Qlora emprega otimizadores paginos, utilizando o recurso de memória unificada da NVIDIA para gerenciamento de memória GPU eficiente. Essas técnicas permitem coletivamente o ajuste fino de alta fidelidade de 4 bits, e efetivamente lidar com restrições de memória.
Métodos dinâmicos de peft O artigo de Dylora (Valipour et al., 2022) apresenta uma nova abordagem para treinar módulos de baixo rank para trabalhar efetivamente em uma variedade de fileiras simultaneamente, eliminando a necessidade de treinar modelos separados para cada classificação.
Inspirados no conceito de abandono aninhado, os autores propõem um método para organizar as representações nos módulos adaptadores de baixo rank. Essa abordagem visa criar adaptadores dinâmicos de baixo rank que possam se adaptar bem a várias fileiras, em vez de serem fixadas em uma única classificação com um orçamento de treinamento definido. Isso é conseguido selecionando dinamicamente as classificações durante o treinamento, permitindo maior flexibilidade sem a necessidade de uma extensa pesquisa de classificação e várias sessões de treinamento de modelos.

Este artigo é Disponível no Arxiv Sob atribuição de licença internacional de atribuição não comercial.










{kind=link}