


Langchain rapidamente se tornou uma estrutura preferida para criar aplicativos poderosos que alavancam grandes modelos de idiomas (LLMS). Enquanto o LLMS se destaca em entender a linguagem humana, o acesso às vastas quantidades de dados estruturados bloqueados nos bancos de dados SQL normalmente requer conhecimento de consulta especializado. Isso levanta uma questão -chave: como podemos capacitar mais usuários a interagir com bancos de dados, como o MySQL, usando linguagem pure e simples?
Este artigo narra minha jornada prática usando Langchain para construir exatamente isso – uma interface de linguagem pure capaz de consultar um banco de dados MySQL. Compartilharei as etapas envolvidas na configuração do sistema usando o Docker, os inevitáveis obstáculos encontrados (incluindo o gerenciamento de limites de token LLM, garantindo privacidade de dados confidenciais e lidar com instruções ambíguas) e as soluções multi-etapas que desenvolvi. Siga para explorar os desafios e sucessos de levar a IA conversacional para bancos de dados relacionais.
A totalidade do código Python, implementando a ferramenta de consulta de linguagem pure discutida aqui, foi gerada com a assistência dos modelos de IA, principalmente ChatGPT e Gemini. Minha função envolveu definir os requisitos, estruturar os avisos, revisar e avaliar o código gerado para funcionalidade e possíveis problemas, orientando a IA por meio de revisões necessárias, integrando os vários componentes e realizando as fases cruciais de teste e depuração.
Etapa 1: estabelecendo a fundação com o Docker
- O objetivo: Crie um ambiente estável e isolado multi-container.
- O método: Minha primeira etapa prática foi criar um ambiente confiável e reproduzível usando o Docker. A arquitetura envolvida três recipientes distintos: um executando o Aplicação de entrance -end (react/node.js)um para o Serviço de again -end (Python com Langchain)e outro dedicado ao Instância do banco de dados MySQL. Essa abordagem de contêiner tornou -se necessária após encontrar dificuldades frustrantes para instalar as bibliotecas Python necessárias localmente devido a conflitos de dependência e incompatibilidades de plataforma.
- Detalhes da configuração: O uso do Docker forneceu uma lousa limpa. Alavancar a assistência da IA ajudou a acelerar a criação do
Dockerfileareiadocker-compose.ymlprecisava definir esses três serviços e suas dependências (como Python, Langchain, Node.js, MySQL Connector). A configuração crítica incluiu a configuração da rede do Docker para a comunicação inter-container necessária (por exemplo, permitindo que o front-end converse com o back-end) e o manuseio de credenciais de banco de dados com segurança usando variáveis de ambiente. - Resultado e transição: Uma vez em execução, os contêineres podem se comunicar adequadamente, fornecendo a infraestrutura necessária. Com esta fundação estabelecida, as etapas a seguir vão Zoom especificamente no design da arquitetura e nos desafios encontrados no serviço Python de again -endcomo é aqui que foram implementados o Core Langchain Logic, LLM orquestração e o pipeline de processamento de dados.


Etapa 2: Primeira dúvida e o desafio do tamanho do esquema
- Sucesso inicial: A configuração de contêiner funcionou, permitindo consultas de linguagem pure bem -sucedida em relação ao banco de dados. Solicitações simples produziram lógica e dados de consulta corretos by way of Langchain e o LLM primário.
- O desafio: limites de token: No entanto, um grande gargalo surgiu rapidamente: erros da API devido ao excedente dos limites do token. Isso aconteceu porque o contexto fornecido ao LLM geralmente inclui detalhes do esquema do banco de dados (nomes de tabela/colunas, tipos) e, com centenas de tabelas, essas informações de esquema tornaram os prompts muito grandes para os limites do LLM.
- A solução alternativa: subconjunto: Minha solução imediata foi restringir as informações do esquema fornecidas ao LLM, talvez apenas considerando um pequeno, definido manualmente subconjunto das tabelas de banco de dados ou usando parâmetros como
top_k=1se aplicável à representação do esquema de manuseio de componentes de componentes Langchain. Isso reduziu significativamente o tamanho rápido e evitou os erros para consultas dentro desse subconjunto. - Limitações: Embora funcional, esta é uma correção quebradiça. O LLM permanece inconsciente de tabelas fora desta visão limitada, impedindo consultas mais complexas e exigindo atualizações manuais. Isso indicou claramente que o manuseio de grandes esquemas de banco de dados requer uma abordagem mais avançada.


Etapa 3: Implementando a filtragem PII/PHI por meio de um immediate de LLM dedicado
- A necessidade crítica de conformidade: Depois de ativar as consultas básicas, a próxima prioridade foi a conformidade com a privacidade de dados. Para empresas, particularmente em setores regulamentados como saúde e bancosfiltrar PII sensível/phi é frequentemente um requisito authorized rigoroso (por exemplo, devido a HIPAA ou regulamentos financeiros) necessários para evitar penalidades graves. Expondo dados brutos também quebram confiança do clientedanos reputaçãoe viola a segurança interna e ética. A filtragem robusta antes de exibir resultados foi, portanto, essencial para atender a essas necessidades de conformidade, especialmente para acesso mais amplo à equipe.
- A solução: um “bot de segurança de dados”: Minha abordagem envolveu a adição de uma camada dedicada de higienização de dados… (O restante do parágrafo que descreve a implementação do filtro LLM permanece o mesmo)
- Lógica de filtragem: Dentro, um immediate detalhado (
get_sanitize_prompt) instruiu este segundo LLM a agir como um “Filtro de privacidade de dados.” Sua tarefa principal period revisar a resposta de texto bruto e o redigo identificado PHI e PII.


- Exemplo: Um resultado como
{'member_id': 12345, 'member_name': 'Jane Doe', 'deal with': '123 Major Avenue, Mercy Metropolis'}seria transformado pelo filtro llm para{'member_id': 12345, 'member_name': '[REDACTED]', 'deal with': '[REDACTED]'}.
Aqui está todo o diagrama após a mudança


Etapa 4: Refinando os avisos para a geração bruta de SQL
- O desafio: interpretação errada: Depois de implementar o filtro PII, abordei o desafio de garantir o principal NL para SQL LLM (
MainLLM) entendi com precisão a intenção do usuário antes executando consultas potencialmente complexas ou ambíguas em relação ao banco de dados. Avisos vagos podem liderarMainLLMPara executar o SQL incorreto, recuperar dados irrelevantes ou falhar. - A solução: um “bot de refinamento rápido”: Para melhorar a confiabilidade da execução, introduzi um preliminar “Bot de refinamento rápido” – uma terceira chamada LLM. Este bot atuou como um “engenheiro de immediate de especialista”, levando a consulta authentic e o esquema de banco de dados para reescrever a solicitação em uma instrução altamente explícita e inequívoca para o
MainLLM. - Objetivo do refinamento: O objetivo period formular um rápido que claramente guiou
MainLLMEm que mesas, colunas e condições eram necessárias, maximizando an opportunity executar a consulta correta contra o banco de dados e recuperar os dados pretendidos. - Resultado: Esta etapa de pré-processamento melhorou significativamente a consistência e a precisão dos dados recuperados por
MainLLM.

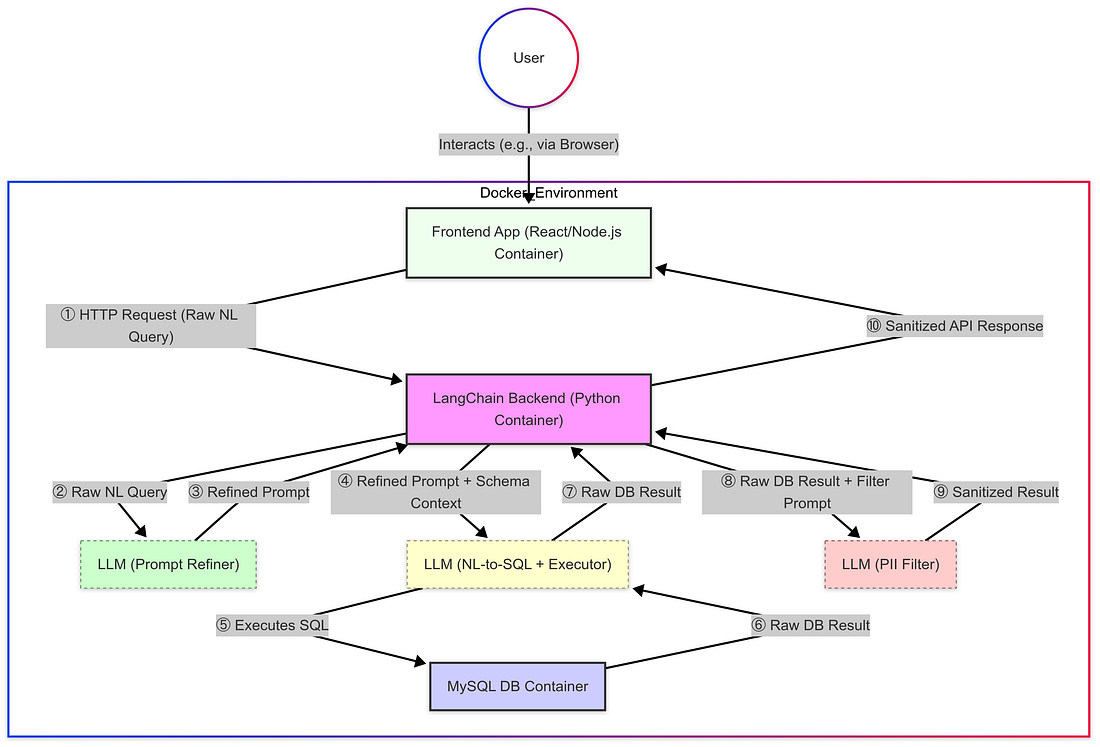
Etapa 5: Aumentando o contexto com memória de conversa
- A necessidade: Para elevar a experiência do usuário além das consultas únicas e permitir um diálogo mais pure, lembrar que o contexto da conversa foi essential para lidar com perguntas de acompanhamento.
- A implementação: Eu integrei os recursos de memória de Langchain usando
ConversationSummaryMemory. Esta abordagem usa um LLM (gpt-3.5-turbonesse caso) para resumir progressivamente a conversa, mantendo o contexto -chave acessível ao gerenciar o uso do token (configurado commax_token_limit=500). - Integração: Isso resumiu
{historical past}foi então incorporado diretamente no modelo imediato usado ao interagir com oMainLLM(o executor NL para SQL +), juntamente com a atual (potencialmente refinada){question}. - Beneficiar: A adição dessa camada de memória permitiu que o sistema considerasse o diálogo em andamento, melhorando significativamente a usabilidade para conversas mais coerentes e com reconhecimento de contexto sobre o conteúdo do banco de dados.
Conclusão: lições da construção de uma interface SQL multi-LLM
Construir essa interface de linguagem pure para o MySQL usando Langchain foi uma jornada reveladora para o poder e as complexidades do desenvolvimento moderno da IA. O que começou como objetivo para consultar um banco de dados usando o inglês simples evoluiu para um pipeline de várias etapas envolvendo três chamadas de LLM distintas: uma para refinar os avisos do usuário, um para traduzir a linguagem pure para SQL e executá-lo diretamente no banco de dados e um terceiro crítico para filtrar PII/PII sensível dos resultados. A integração da memória de conversação aprimorou ainda mais a usabilidade, permitindo interações mais naturais e com reconhecimento de contexto.
Os principais desafios, como gerenciar limites de token LLM com grandes esquemas, garantir a privacidade dos dados por meio da filtragem e melhorar o entendimento imediato exigia soluções iterativas. Ao alavancar a IA para a geração de código, as partes aceleraram o processo, projetando a arquitetura geral, implementando lógica específica como as exceções do filtro PII, integrando componentes e testes rigorosos permaneceram tarefas cruciais orientadas pelo homem.
Próximas etapas: Explorando a geração de recuperação (RAG)
A taxa de sucesso, especialmente para consultas mais complexas ou ambíguas, indica oportunidades claras de melhoria além das técnicas atuais de engenharia e filtragem.
Uma avenida promissora que pretendo explorar ao lado de aumentar ainda mais a precisão é Geração de recuperação usededed (RAG). Em vez de confiar apenas no conhecimento interno do LLM ou em uma visão estática do esquema, o RAG introduz uma etapa de recuperação dinâmica. Antes de gerar o SQL, um sistema de pano pesquisaria uma base de conhecimento especializada para obter informações altamente relevantes para a consulta atual do usuário.
Neste contexto NL para SQL, isso pode envolver a recuperação:
- Descrições ou documentação detalhadas para as tabelas e colunas de banco de dados específicas consideradas mais relevantes para a consulta.
- Exemplos de perguntas semelhantes em linguagem pure anteriormente mapeadas para suas contrapartes corretas do SQL.
- Regras ou definições de negócios relevantes referentes aos dados solicitados.
Esta informação direcionada e recuperada é então adicionada (“aumentada”) ao immediate enviado para o principal NL para SQL LLM (MainLLM), proporcionando-o com um contexto mais rico e justo. A hipótese é que esse contexto dinâmico melhorará significativamente o entendimento e a capacidade do LLM de gerar SQL precisos, oferecendo potencialmente melhorias substanciais sem os extensos requisitos de conjunto de dados de ajuste fino. A implementação e a avaliação de uma estratégia de RAG eficaz representa a próxima fase emocionante para melhorar essa interface de banco de dados de conversação.
")





")



")


{kind=link}