


::: informações
Autores:
(1) Opher Lieber, com igual contribuição; (2) Barak Lenz, com igual contribuição; (3) Hofit Bata; (4) Gal Cohen; (5) Jhonathan Osin; (6) Itay Dalmedigos; (7) Erez Safahi; (8) Meirom abalado; (9) Yonatan Belinkov; (10) Shai Shalev-Shwartz; (11) OMRI AMEND; (12) Raz Alon; (13) Tomer Asida; (14) Amir Bergman; (15) Roman Glozman; (16) Michael Gokhman; (17) Avashalom Manevich; (18) Nir Ratner; (19) Noam Rozen; (20) Erez Shwartz; (21) Mor Zusman; (22) Yoav Shoham.
:::
Tabela de hyperlinks
Parte 1
Parte 2
Parte 3
Parte 4
Parte 5
Parte 6
3. colhendo os benefícios
3.1 Implementação de Jamba para uma única GPU de 80 GB
A configuração específica em nossa implementação foi escolhida para caber em uma única GPU de 80 GB, enquanto alcançava o melhor desempenho no sentido de qualidade e taxa de transferência. Em nossa implementação, temos uma sequência de 4 blocos de jamba. Cada bloco Jamba tem a seguinte configuração:
• l = 8: o número de camadas.
• A: M = 1: 7: Camadas de atenção-mamba.
• e = 2: Com que frequência usar o MOE em vez de um único MLP.
• n = 16: Número complete de especialistas.
• ok = 2: Número de principais especialistas usados em cada token.
A proporção A: M = 1: 7 foi escolhida de acordo com as ablações preliminares, como mostrado na seção 6, pois essa proporção period a variante mais eficiente em computação entre as variantes de melhor desempenho em termos de qualidade.
A configuração dos especialistas foi escolhida para permitir que o modelo se encaixe em uma única GPU de 80 GB (com pesos INT8), incluindo memória suficiente para as entradas. Em specific, N e E foram equilibrados para ter uma média de ~ 8 especialistas por camada. Além disso, equilibramos N, Okay e E para permitir a alta qualidade, mantendo os requisitos de computação e as dependências de comunicação (transferências de memória) verificadas. Consequentemente, optamos por substituir o módulo MLP por MOE em todas as outras camadas, bem como um complete de 16 especialistas, dois dos quais são usados em cada token. Essas opções foram inspiradas em trabalhos anteriores no MOE [7, 49] e verificado em experimentos preliminares.
A Figura 2 mostra o comprimento máximo do contexto que se encaixa em uma única GPU de 80 GB com nossa implementação do JAMBA em comparação com o mixtral 8x7b e o llama-2-70b. Jamba fornece 2x o comprimento do contexto de mixtral e 7x o da llama-2-70b.
No geral, nossa implementação do Jamba foi treinada com sucesso em comprimentos de contexto de até 1 milhão de tokens. O modelo lançado suporta comprimentos de até 256 mil tokens.
3.2 Análise de taxa de transferência
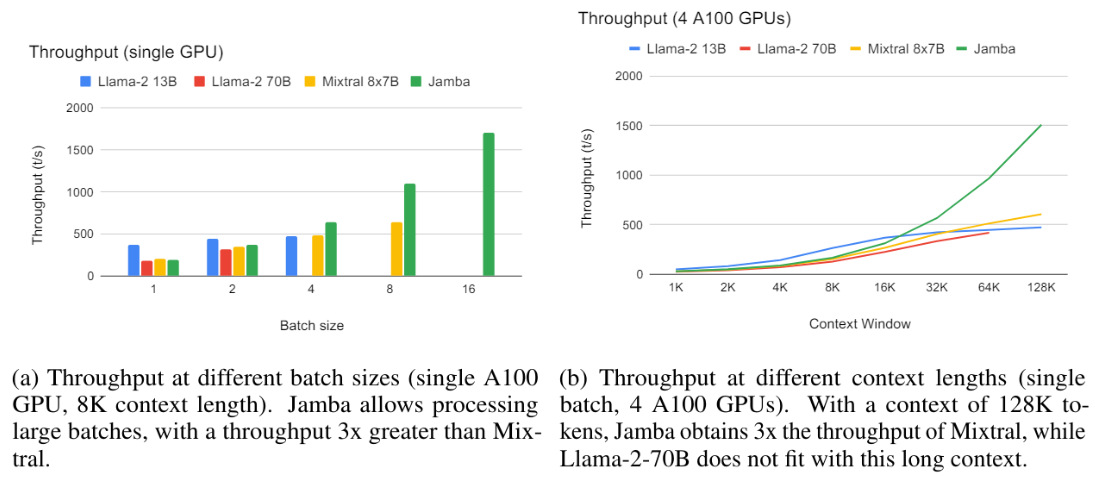
Para concretude, apresentamos os resultados da taxa de transferência em duas configurações específicas.[3] Na primeira configuração, temos o tamanho variável do lote, uma única GPU A100 80 GB, quantização INT8, comprimento do contexto de 8k, gerando saída de 512 tokens. Como mostra a Figura 3A, o Jamba permite o processamento de lotes grandes, levando a um aumento de 3x na taxa de transferência (tokens/segundo) sobre o mixtral, que não se encaixa com um lote de 16, apesar de ter um número semelhante de parâmetros ativos.
Na segunda configuração, temos um único lote, 4 GPUs A100, sem quantização, comprimentos de contexto variados, gerando saída de 512 tokens. Como demonstrado na Figura 3b, em pequenos comprimentos de contexto, todos os modelos têm uma taxa de transferência semelhante. Jamba se destaca em longos contextos; Com 128k tokens, sua taxa de transferência é 3x a do mixtral. Observe que isso ocorre apesar do fato de Jamba ainda não ter desfrutado de otimizações do tipo que a comunidade se desenvolveu para modelos de transformadores puros nos últimos seis anos. Podemos esperar que a lacuna passada aumente, pois essas otimizações também são desenvolvidas para o Jamba.
4. Infraestrutura de treinamento e conjunto de dados
O modelo foi treinado nas GPUs Nvidia H100. Utilizamos uma estrutura proprietária interna, permitindo treinamento eficiente em larga escala, incluindo FSDP, paralelismo tensoras, paralelismo de sequência e paralelismo especializado.
Jamba é treinado em um conjunto de dados interno que contém dados de texto da net, livros e código, com a última atualização em março de 2024. Nosso pipeline de processamento de dados inclui filtros de qualidade e desduplicação.
::: Information este artigo é Disponível no Arxiv sob a licença CC BY-SA 4.0 Deed.
:::
[3] Referindo-se à taxa de transferência de ponta a ponta (codificação+decodificação). Os resultados devem ser obtidos relativamente e não absolutamente, pois são sem possíveis otimizações.













{kind=link}