


Você já olhou para as notícias e se pergunta sobre o processo por trás do ciclo de notícias? Eu fiz, e nas últimas duas décadas, foi objeto de um dos meus projetos. O Raspberry Pi na minha prateleira corre minha ferramenta de análise de tendência de palavra para conteúdo de notíciasE desde minha jornada do Curious Geek até ter meu próprio grande sistema de análise de corpus levou vinte anos, vale a pena uma segunda olhada.
Como a turbulência da carreira levou a um projeto de duas décadas

Em meados da década de 2000, saí da falha do Dotcom quase intacta e estava trabalhando para uma pequena loja de web. Quando eles fugiram, eu estava lançando como um, e passou um tempo como Um avaliador de qualidade do Google Enquanto eu procurava um novo emprego de permissão. Essas equipes são empregadas pela gigante de busca por meio de agências de emprego temporárias e, em termos frouxos, seu trabalho é ser os macacos treinados contra os quais o algoritmo é testado. O algoritmo escolheu X e, se os humanos também escolherem X, o algoritmo provavelmente está acertando. Ser um avaliador de qualidade não é de forma alguma um trabalho de alto perfil, mas com o grande G brilhante no meu currículo, logo me encontrei em demanda de empresas da Web que buscam algum conhecimento de marketing de mecanismos de pesquisa de Hat White. O que aprendi espelhou minha lição de uma década anterior no negócio de CD-ROM, que, na web, como em qualquer outro meio de publicação eletrônica, o bom conteúdo bem apresentado tem prioridade sobre quaisquer truques de chapéu preto.
Mas o que faz um bom conteúdo? Esqueça uma obsessão por encher palavras -chave falsas no texto e, em vez disso, falar sobre as coisas certas e faça com autoridade. Quais são as coisas certas neste contexto? Se você está cobrindo um assunto, precisará fazê -lo usando o idioma certo; Aquilo que a maioria usa, em vez de apenas a linguagem, você usa. Eu posso pensar em vários exemplos dos quais provavelmente não deveria falar, mas um exemplo perto de casa para mim vem na cidra. No Reino Unido, a cidra é uma bebida alcoólica fermentada feita de maçãs e, como cidrayker artesanal de muitos anos, tenho uma boa compreensão de seu vocabulário. A ortografia aceita é “cidra”, mas há uma ortografia alternativa de “Cyder” usada por alguns produtores comerciais da bebida. Não demora muito para perceber que on -line, quase ninguém usa Cyder com um y e, assim, as páginas concentradas nessa palavra se sairão menos do que aquelas que falam sobre sidra.
Comecei a criar software para analisar a linguagem em torno de um determinado tópico, com o objetivo de discernir a cidra metafórica do Cyder. Foi uma grande surpresa alguns anos depois descobrir que eu havia inventado para mim o campo já existente da lingüística computacional, algo que teria me salvado muito tempo se eu soubesse sobre isso quando comecei. Eu estava pegando um corpus de texto e calculando as frequências e colocados (palavras que aparecem juntamente um com o outro) das palavras dentro dele, e a partir disso eu podia ver rapidamente qual redação importava em torno de um assunto e o que não o fez. Isso levou perfeitamente a um interesse em como seria o mesmo processo para os dados de notícias com um eixo de tempo adicionado, então criei uma versão que colheu seu corpus a partir de feeds RSS. Assim começou meu projeto de décadas.
Da ideia do projeto, ao aparelho corpus
Em 2005, eu sabia como criar sites da maneira do dia, então usei as ferramentas que tinha. Php5 e MySQL. Eu sei que o PHP é fora de moda hoje em dia, mas na época isso não era muito controverso e, além de todo o código de PHP de qualidade questionável por aí, continua sendo uma linguagem de script útil. Usar o MySQL, no entanto, me causaria imensos problemas. Eu tinha feito o que parecia a coisa certa e criei um banco de dados estruturado com tabelas vinculadas, mas não apreciei totalmente o quão grande era a tarefa que eu havia assumido. A colheita da BSS Firehose em vários meios de comunicação traz milhares de histórias a cada semana; portanto, as consultas quase intantâneas durante meus primeiros estágios de desenvolvimento cresceram para levar muitos minutos à medida que meu corpus se expandia. Estava na hora de criar uma alternativa, e eu a encontrei nos recursos mais básicos do sistema operacional, o sistema de arquivos.
Voltando aos anos 90, quando você pagou pela hospedagem na web, foi dado em termos de espaço de armazenamento. O poder de processamento necessário para executar seus scripts CGI ou intérpretes posteriores do servidor, como ASP ou PHP, não foi considerado. Assim, tornou -se prática normal tentar reduzir o uso de armazenamento e não pensar em processamento, e eu tinha sem pensar seguir esse caminho.
Mas na década de 2000, o preço do armazenamento havia caído enormemente enquanto o processamento não. Esta foi a década em que os serviços em nuvem, como a AWS, apareceram e, além de comprar discos rígidos de muitos gigabytes por não muito, você também pode alugar pela primeira vez um balde de nuvem por centavos. Meu sistema de análise de corpus não precisava gastar todo o tempo computando se eu pudesse usar um disco rígido terabyte para compensar menos uso do processador, então virei meu sistema na cabeça. Ao coletar as histórias do RSS, meu script de recuperação pré-computaria os dados finais e o armazenaria em uma vasta árvore de pequenos arquivos JSON acessíveis em alta velocidade através do sistema de arquivos, e então meu software de análise poderia simplesmente recuperá-los e fazer seu relatório. O sistema passou de um laptop x86 trabalhador para um Raspberry Pi com um disco rígido USB com um disco USB, e lá permaneceu de alguma forma desde então.
O que isso pode fazer?
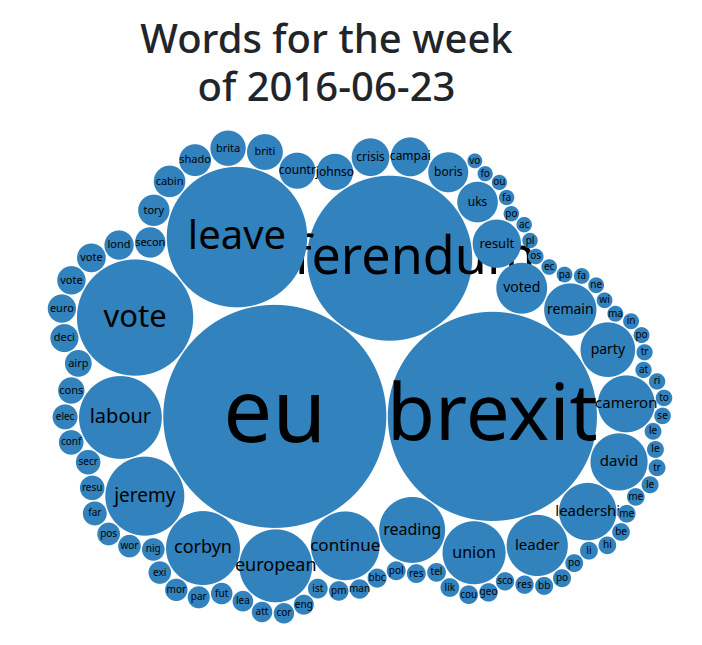
Então, eu tenho um corpus de notícias que me levou muito tempo para construir. Eu posso pegar uma ou mais palavras e comparar a ocorrência deles ao longo do tempo. Eu posso assistir ao ciclo de notícias, posso ver histórias se acumulando com o tempo. Eu posso até ver tendências que às vezes vão contra a opinião recebida, como identificar isso O eventual vencedor da corrida de liderança trabalhista do Reino Unido provavelmente será Jeremy Corbyn No início, enquanto o rebanho estava olhando para outro lugar. Às vezes, como no desempenho da palavra “Brexit”, no meio da última década, posso ver os grandes eventos de nossos tempos em alívio Stark, mas talvez seja um pouco obsceno que haja mais valor. Se você seguir um tópico e de repente seca por alguns dias, espere uma história realmente grande no terceiro dia, por exemplo. Também posso ver quais pontos de venda cobrem uma história mais do que outra, algo útil ao tentar determinar se um tópico está sendo empurrado em nome de um lobby em particular.
Meu experimento na análise de texto transformou -se em algo muito mais, mesmo ouso dizer, algo que encontro ajuda para descobrir o que realmente está acontecendo em tempos turbulentos. Mas, do ponto de vista da tecnologia, isso me ensinou uma quantidade enorme, sobre estatísticas, sobre linguagem, análise de texto e até mesmo de assistir ao número de inodos disponíveis em um disco rígido. Acredite, muitos milhões de pequenos arquivos em uma árvore podem se tornar pesados. Mas talvez acima de tudo, depois de uma vida inteira de mexer com todos os tipos de projetos, mas gerando pouco significado duradouro, posso olhar para este e dizer que criei algo útil. E isso é algo para ser feliz.









")

{kind=link}