


Neste blog, passaremos por um exemplo abrangente de indexação de documentos de pesquisa com extração de diferentes metadados – além de Chunking e incorporação de texto completo – e construir incorporações semânticas para indexação e consulta.
Nós apreciaríamos muito se você pudesse ⭐ Star Cocoindex no Github Se você achar útil este tutorial.
Casos de uso
- Pesquisa acadêmica e recuperação, bem como agentes de IA baseados em pesquisa
- Sistemas de recomendação em papel
- Gráficos de conhecimento de pesquisa
- Análise semântica da literatura científica
O que vamos alcançar
Vamos dar uma olhada neste PDF como exemplo.

Aqui está o que queremos realizar:
- Extraia os metadados do artigo, incluindo nome do arquivo, título, informações do autor, resumo e número de páginas.
- Construa incorporações de vetor para os metadados, como o título e o abstrato, para pesquisa semântica.

Isso permite melhores resultados de pesquisa semântica de metadados. Por exemplo, você pode combinar consultas de texto com títulos e resumos.
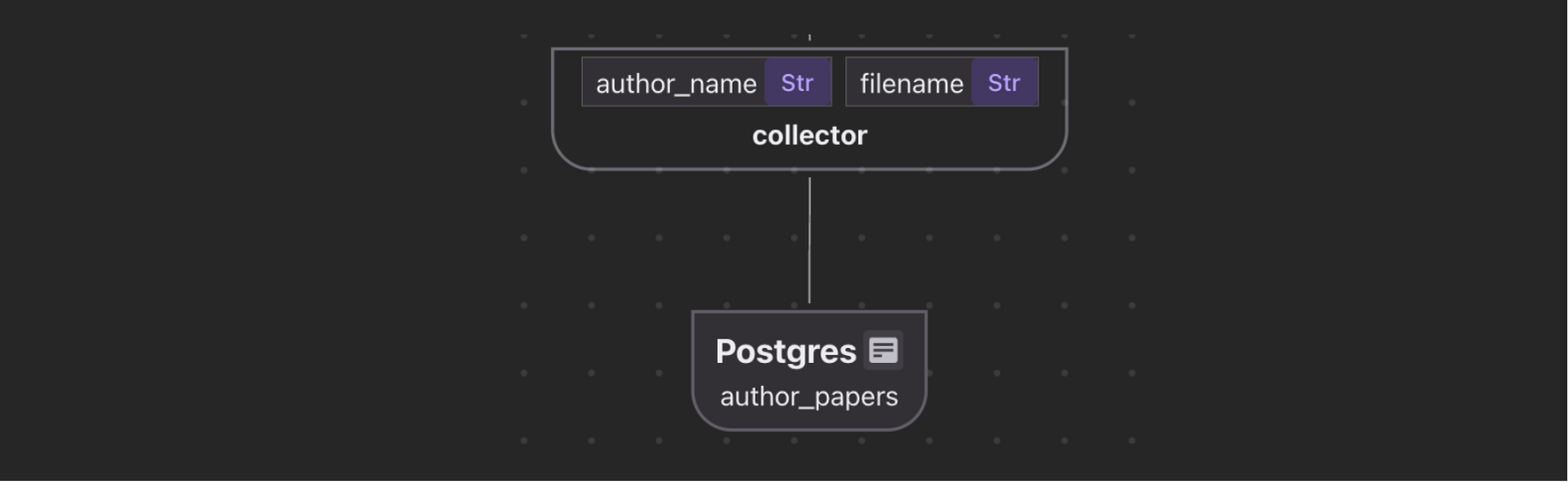
- Crie um índice de autores e todos os nomes de arquivos associados a cada autor para responder a perguntas como “Dê -me todos os trabalhos de Jeff Dean”.
- Se você deseja realizar incorporação completa em PDF para o artigo, também pode consultar este artigo.
Você pode encontrar o código completo aqui.
Se este artigo for útil para você, dê -nos uma estrela ⭐ no Github para nos ajudar a crescer.
Componentes principais
- Pré -processamento em PDF
- Lê PDFs usando
pypdfe extratos:- Número total de páginas
- Conteúdo da primeira página (usado como proxy para informações ricas em metadados)
- Lê PDFs usando
- Conversão de marcação
- Converte a primeira página em Markdown usando marcador.
- Extração de metadados movidos a LLM
- Envia o markdown de primeira página para o GPT-4O usando o Cocoindex’s
ExtractByLlmfunção. - Metadados extraídos incluem e muito mais.
title(corda)authors(com nome, email e afiliação)abstract(corda)
- Envia o markdown de primeira página para o GPT-4O usando o Cocoindex’s
- Incorporação semântica
- O título está incorporado diretamente usando o
all-MiniLM-L6-v2Modelo pelo Sinerencetransformer. - Os resumos são fundidos com base na pontuação semântica e na contagem de token, então cada pedaço é incorporado individualmente.
- O título está incorporado diretamente usando o
- Coleta de dados relacionais
- Os autores são desenrolados e coletados em um
author_papersrelação, permitindo consultas como:- Mostre todos os papéis por x
- Quais co-autores trabalharam com Y?
- Os autores são desenrolados e coletados em um
Pré -requisitos
Como alternativa, temos apoio nativo a Gêmeos, Ollama, Litellm, checkout o guia.
Você pode escolher seu provedor LLM favorito e pode trabalhar completamente no local.
Defina o fluxo de indexação
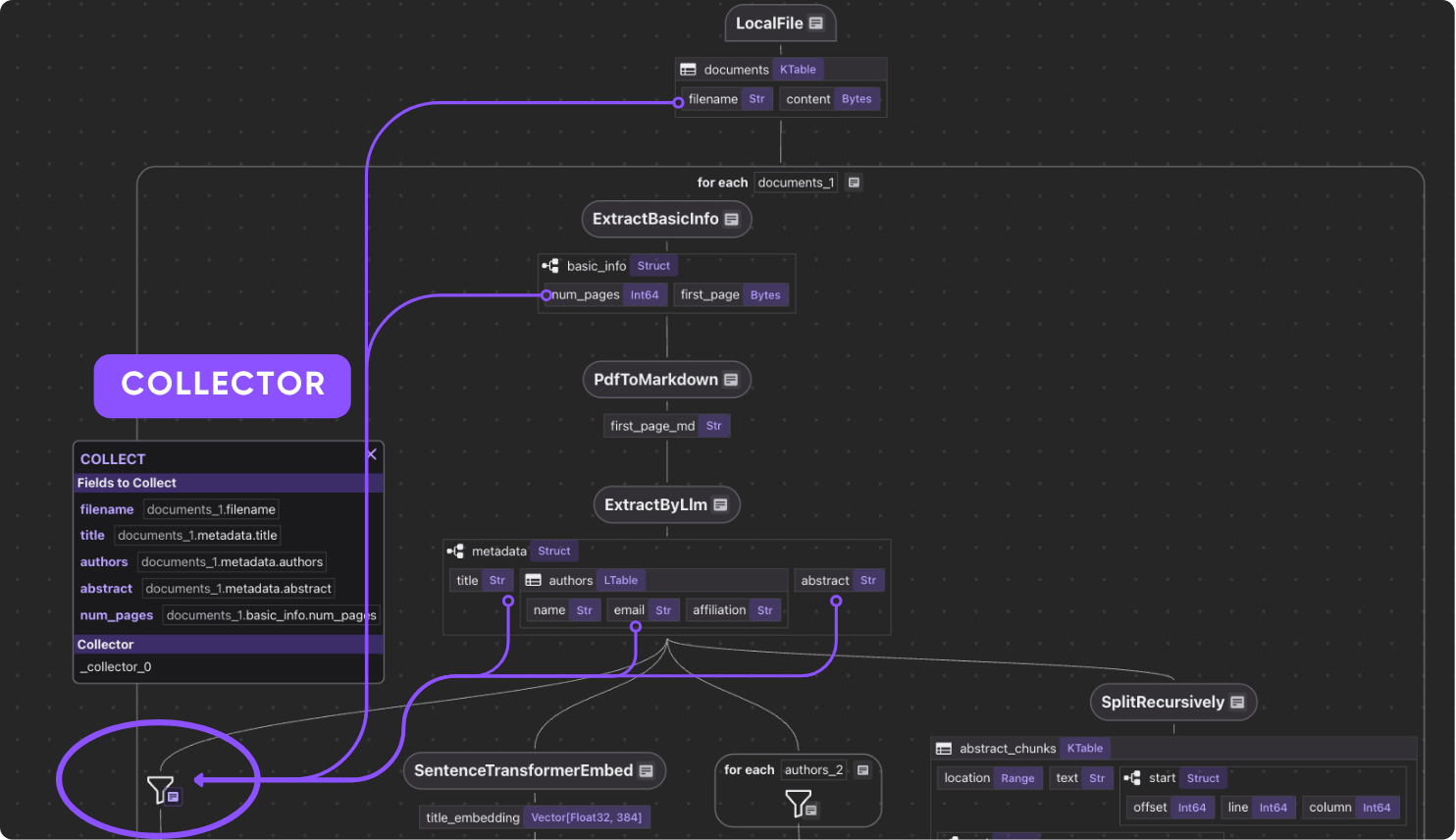
Este projeto demonstra um exemplo um pouco mais abrangente de metadados que entendem mais próximos dos casos de uso do mundo real.

Você verá como é fácil alcançar esse design pelo CocoIndex dentro de 100 linhas de lógica de indexação – código.
Para ajudá -lo a navegar melhor no que passaremos, aqui está um diagrama de fluxo.
- Importe uma lista de artigos em PDF.
- Para cada arquivo:
- Extraia a primeira página do papel.
- Converta a primeira página em Markdown.
- Extrair metadados (título, autores, resumo) da primeira página.
- Divida o resumo em pedaços e calcule incorporações para cada pedaço.
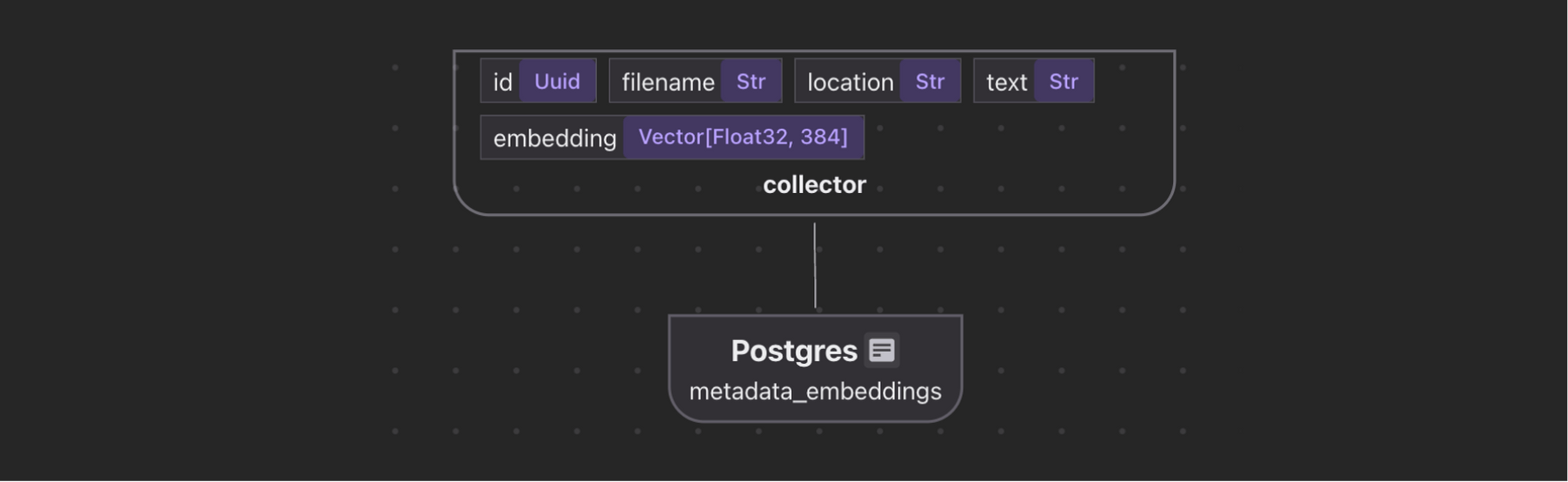
- Exportar para as tabelas a seguir no Postgres com o PGVector:
- Metadados (título, autores, resumo) para cada artigo.
- Mapeamento de autor a papel, para consulta baseada em autor.
- Incorporação para títulos e pedaços abstratos, para pesquisa semântica.
Vamos zoom nas etapas.
Importar os papéis
@cocoindex.flow_def(name="PaperMetadata")
def paper_metadata_flow(
flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope
) -> None:
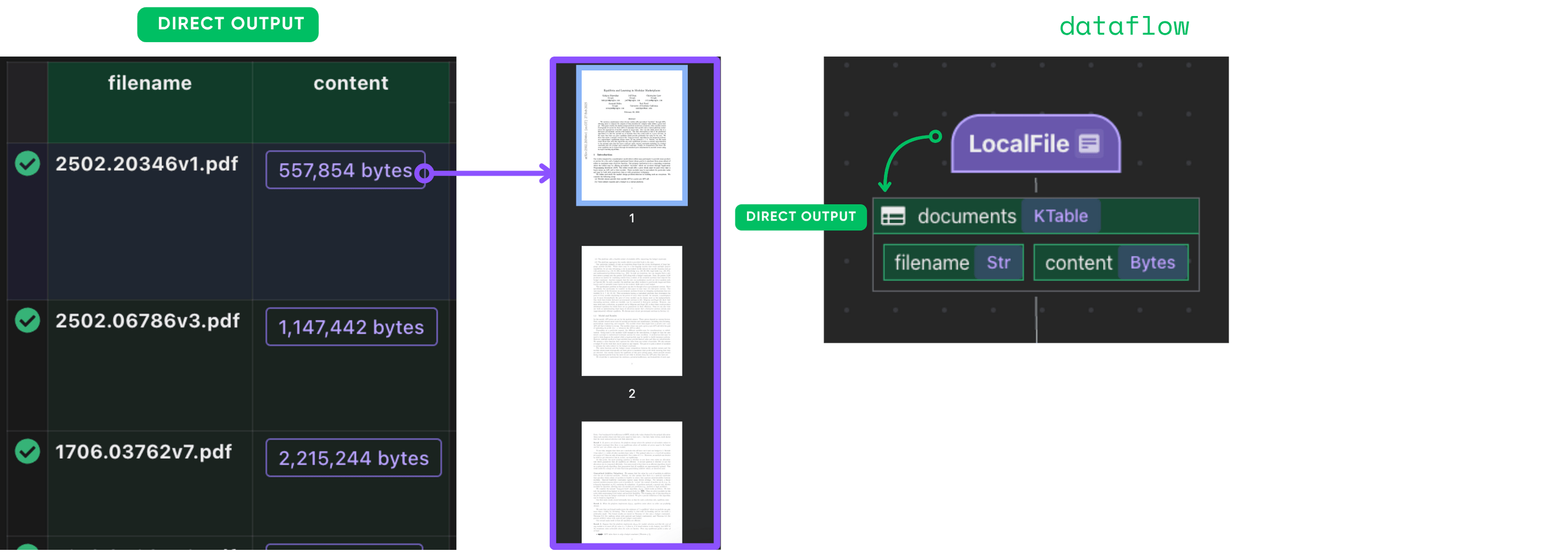
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="papers", binary=True),
refresh_interval=datetime.timedelta(seconds=10),
)
flow_builder.add_source criará uma tabela com sub -campos (filenameAssim, content),
Podemos nos referir à documentação para obter mais detalhes.
Extrair e coletar metadados
Defina uma função personalizada para extrair a primeira página e o número de páginas do PDF.
@dataclasses.dataclass
class PaperBasicInfo:
num_pages: int
first_page: bytes
@cocoindex.op.function()
def extract_basic_info(content: bytes) -> PaperBasicInfo:
"""Extract the first pages of a PDF."""
reader = PdfReader(io.BytesIO(content))
output = io.BytesIO()
writer = PdfWriter()
writer.add_page(reader.pages[0])
writer.write(output)
return PaperBasicInfo(num_pages=len(reader.pages), first_page=output.getvalue())
Agora, conecte isso ao seu fluxo.
Extraímos metadados da primeira página para minimizar o custo de processamento, pois todo o PDF pode ser muito grande.
with data_scope["documents"].row() as doc:
doc["basic_info"] = doc["content"].transform(extract_basic_info)
Após esta etapa, você deve ter as informações básicas de cada artigo.

Analisar informações básicas
Converteremos a primeira página em Markdown usando marcador.
Como alternativa, você pode conectar facilmente seu analisador PDF favorito, como documentos.
Defina uma função de conversor de marcadores e cache-a, pois sua inicialização é intensiva em recursos.
Isso garante que a mesma instância do conversor seja reutilizada para diferentes arquivos de entrada.
@cache
def get_marker_converter() -> PdfConverter:
config_parser = ConfigParser({})
return PdfConverter(
create_model_dict(), config=config_parser.generate_config_dict()
)
Conecte -o a uma função personalizada.
@cocoindex.op.function(gpu=True, cache=True, behavior_version=1)
def pdf_to_markdown(content: bytes) -> str:
"""Convert to Markdown."""
with tempfile.NamedTemporaryFile(delete=True, suffix=".pdf") as temp_file:
temp_file.write(content)
temp_file.flush()
text, _, _ = text_from_rendered(get_marker_converter()(temp_file.name))
return text
Passe para sua transformação
with data_scope["documents"].row() as doc:
doc["first_page_md"] = doc["basic_info"]["first_page"].transform(
pdf_to_markdown
)
Após esta etapa, você deve ter a primeira página de cada artigo no formato de marcação.

Defina um esquema para extração de LLM. O CocoIndex suporta a extração estruturada por LLM com esquemas complexos e aninhados.
Se você estiver interessado em aprender mais sobre esquemas aninhados, consulte este artigo.
@dataclasses.dataclass
class PaperMetadata:
"""
Metadata for a paper.
"""
title: str
authors: list[Author]
abstract: str
Conecte -o ao ExtractByLlm função. Com um dataclass definido, o CocoIndex analisará automaticamente a resposta LLM no dataclass.
doc["metadata"] = doc["first_page_md"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4o"
),
output_type=PaperMetadata,
instruction="Please extract the metadata from the first page of the paper.",
)
)
Após esta etapa, você deve ter os metadados de cada artigo.
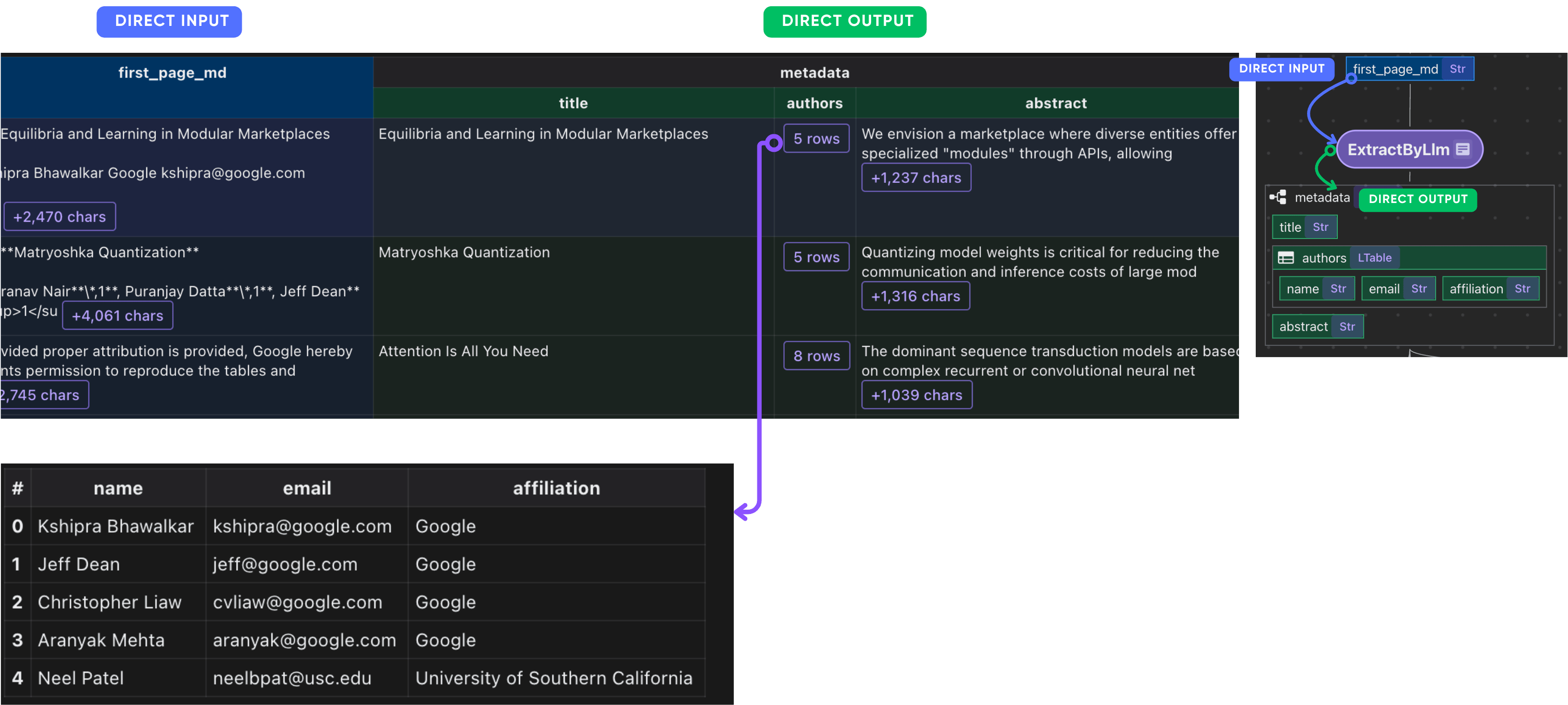
Colete metadados em papel
paper_metadata = data_scope.add_collector()
with data_scope["documents"].row() as doc:
# ... process
# Collect metadata
paper_metadata.collect(
filename=doc["filename"],
title=doc["metadata"]["title"],
authors=doc["metadata"]["authors"],
abstract=doc["metadata"]["abstract"],
num_pages=doc["basic_info"]["num_pages"],
)
Apenas colete tudo o que você precisa 🙂
Coletar author para filename Informação
Já extraímos a lista de autores. Aqui, queremos coletar artigos do autor → em uma tabela separada para criar uma funcionalidade de pesquisa.
Simplesmente colete pelo autor.
author_papers = data_scope.add_collector()
with data_scope["documents"].row() as doc:
with doc["metadata"]["authors"].row() as author:
author_papers.collect(
author_name=author["name"],
filename=doc["filename"],
)
Calcular e coletar incorporados
Título
doc["title_embedding"] = doc["metadata"]["title"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"
)
)

Resumo
Divida resumo em pedaços, incorpore cada pedaço e colete suas incorporações.
Às vezes, o resumo pode demorar muito.
doc["abstract_chunks"] = doc["metadata"]["abstract"].transform(
cocoindex.functions.SplitRecursively(
custom_languages=[
cocoindex.functions.CustomLanguageSpec(
language_name="abstract",
separators_regex=[r"[.?!]+\s+", r"[:;]\s+", r",\s+", r"\s+"],
)
]
),
language="abstract",
chunk_size=500,
min_chunk_size=200,
chunk_overlap=150,
)
Após esta etapa, você deve ter os pedaços abstratos de cada artigo.

Incorpore cada pedaço e colete suas incorporações.
with doc["abstract_chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"
)
)
Após esta etapa, você deve ter as incorporações dos pedaços abstratos de cada artigo.
Colete incorporação
metadata_embeddings = data_scope.add_collector()
with data_scope["documents"].row() as doc:
# ... process
# collect title embedding
metadata_embeddings.collect(
id=cocoindex.GeneratedField.UUID,
filename=doc["filename"],
location="title",
text=doc["metadata"]["title"],
embedding=doc["title_embedding"],
)
with doc["abstract_chunks"].row() as chunk:
# ... process
# collect abstract chunks embeddings
metadata_embeddings.collect(
id=cocoindex.GeneratedField.UUID,
filename=doc["filename"],
location="abstract",
text=chunk["text"],
embedding=chunk["embedding"],
)
Exportar
Finalmente, exportamos os dados para o Postgres.
paper_metadata.export(
"paper_metadata",
cocoindex.targets.Postgres(),
primary_key_fields=["filename"],
)
author_papers.export(
"author_papers",
cocoindex.targets.Postgres(),
primary_key_fields=["author_name", "filename"],
)
metadata_embeddings.export(
"metadata_embeddings",
cocoindex.targets.Postgres(),
primary_key_fields=["id"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY,
)
],
)
Neste exemplo, usamos o PGVector como lojas de incorporação/
Com o CocoIndex, você pode fazer um interruptor de linha em outros bancos de dados de vetores suportados, como o QDRANT, consulte este guia para obter mais detalhes.
Nosso objetivo é padronizar interfaces e torná -lo como construir Lego.
Vista em Cocoinsight passo a passo
Você pode percorrer o projeto passo a passo em Cocoinsight para ver
Exatamente como cada campo é construído e o que acontece nos bastidores.
Consulte o índice
Você pode se referir a esta seção de incorporações de texto sobre
Como construir consulta contra incorporações.
Por enquanto, o CocoIndex não fornece interface de consulta adicional. Podemos escrever SQL ou confiar no mecanismo de consulta pelo armazenamento de destino.
- Muitos bancos de dados já otimizaram implementações de consulta com suas próprias práticas recomendadas
- O espaço de consulta possui excelentes soluções para consulta, reranger e outras funcionalidades relacionadas à pesquisa.
Se você precisar de ajudar na redação da consulta, sinta -se à vontade para nos alcançar na Discord.
Apoie -nos
Estamos constantemente melhorando, e mais recursos e exemplos estão chegando em breve.
Se este artigo for útil para você, dê -nos uma estrela ⭐ no Github para nos ajudar a crescer.
Obrigado pela leitura!













{kind=link}